Artash Nath, Grade 10 Student, Toronto Reflections from my year-long journey that I started at end of Grade 7 by enrolling myself in the University of Toronto School of Continuing […]
Artash Nath, Grade 10 Student, Toronto
Reflections from my year-long journey that I started at end of Grade 7 by enrolling myself in the University of Toronto School of Continuing Studies for a Certificate Program in Artificial Intelligence. I completed all three courses on machine learning, deep learning using neural nets, and reinforcement learning and applied them to my ongoing projects on space, health, and robotics. I completed my middle school, won a Gold Medal for my project on “Using Machine Learning to Remove Noise from Stellar Spots in Exoplanetary Data from Space Telescopes” at the INSPO North America Science Fair 2020, and obtained my Certificate in Artificial Intelligence from the University of Toronto.
Getting a Certificate in Artificial Intelligence from the University of Toronto after a year-long journey while finishing Middle School
I am passionate about solving ongoing and emerging global challenges- from climate change to ocean noise to deep space exploration and ethical artificial general intelligence. And I like to tackle these challenges by using real-world data, analysis and simulations, and technology for good. This persuades me to be in a perpetual knowledge-seeking mode so that I have access to the latest tools, innovations, networks, and intelligence to tackle the challenges from a new perspective.
Since I was 7 years, I have been working on open hardware and software projects on my own. I started building robots, rovers, rockets, drones using Arduino, Micro: bit, and Raspberry Pi. Later, I started writing machine learning algorithms to seed automation and intelligence in hardware projects for obstacle avoidance, emotion detection, multimodal data processing, and natural language processing. I gleaned the knowledge required for undertaking these projects over the years. I started by attending free workshops with community organizations such as CoderDojo, Canada Learning Code, and Kids Code Jeunesse.
Once I got my personal computer, I started taking online courses on Coursera and EdX and following YouTube tutorials such as 3Blue 1Brown and Kaggle. The diverse learning sources meant that learning was always fun, visual, interest-driven, and I could learn at my pace. When I faced problems, Stack Overflow, Confluence, and GitHub became my go-to resources. Over time, I exhausted many of the resources. Many of these resources provided very good fundamental knowledge about a subject but did not go in-depth or provide the essential rigor to fully master the subject. Some of these resources were narrowly limited to a particular technology, application, or software which made them less appealing.
Admission at School of Continuing Studies at the University of Toronto
To satiate my quest for knowledge, I started researching other sources of knowledge, particularly in artificial intelligence so that I could develop a strong theoretical, mathematical, and analytical foundation on the subject. Only then one can start innovating and developing custom applications for projects being pursued. My search led me to the courses offered by the University of Toronto at their St. George Campus in downtown Toronto. I was particularly attracted to their courses on artificial intelligence offered by the School of Continuing Studies.
The University offered a Certificate Course on Artificial Intelligence which comprised three challenging courses on machine learning, deep learning using neural nets, and reinforcement learning taught by top professionals. Together these courses would explore all modern branches of artificial intelligence, provide opportunities to use real-world techniques and programs to solve problems and develop innovative industrial, commercial, and government applications.
I was enthused and determined to undertake all three courses to get my University of Toronto Certificate in Artificial Intelligence. Each course was approximately 36 hours, and the classes (of three hours duration) were held at the University of Toronto Campus in the evening once a week. So, each course was a commitment of at least 3 months. It suited me well as I could balance coursework with my other academic and extra-curricular commitments.
Delivering Project Presentation on Machine Learning at the University of Toronto
But I was only in Grade 7 and was not sure I would be able to apply to these courses, get admitted, and attend these courses physically on the campus. And yet, I knew the one definite way I would not get admitted would be if I did not apply. Optimistically, I went through the application process, checked the pre-requisites, and then applied to them. On the course website, it was recommended to take the preliminary course: Learn to Program- The Fundamentals offered by University of Toronto/Coursera (Free) https://www.coursera.org/learn/learn-to-program I had already taken that course and it was a breeze.
I was elated when I got a confirmation that I was enrolled in these courses. I got my University of Toronto ID number as well as login details for the Quercus intranet where the course details, lecture notes, and other support material would be posted. This was a start of an interesting journey. I was excited for my first class at the University of Toronto campus, to meet my professors and fellow students, and get the learning started!
The first course of the AI Certificate was SCS3253 – Machine Learning. This course focused on the fundamentals of analyzing data and building basic predictive models using different machine learning algorithms. The course instructor was Dean Rootenberg, a data scientist and a senior manager at TD Bank. Mr. Rootenberg had a wealth of experience working on big data and analytics projects. Consequently, he was seamlessly able to communicate the course material in a way that was easy to understand and was interspersed with many real-world examples.
The sessions took place in a hall at the Bahen Centre for Information Technology in the University of Toronto, St. George campus. Each session was divided into 2 parts- theory, and application. In the first part of the session, the instructor covered the theory behind the algorithms or methods we were studying, using a blackboard and a projector. Then, after a short break, we would apply and experiment with those algorithms in Python on a Jupyter Notebook. We also had assignments due every 2 or 3 weeks where we would put our learnings from class into practice.
The first thing covered in the class was how machine learning differentiated itself from classical computer programs. After a class discussion on the topic, we came up with several key ideas. This included machine learning’s ability to learn and improve over time and making decisions in new environments with no human input. Then, we took a recap of the history of research and breakthroughs in machine learning. Starting from Mark 1, the first successful neurocomputer built for image recognition by IBM in 1959, and the various struggles by researchers in the field to expand machine learning to tackle more complex problems. It was only in the 1990s where machine learning started to flourish.
The first main algorithm we worked on was clustering. Clustering works by automatically recognizing natural groupings in data. I learned about how certain clustering algorithms can work better in some types of datasets. For example, K-Means, a simple and popular clustering method works try to cluster the data into a predefined number of clusters and keep the centroids as small as possible. On the other hand, Density-Based Spatial Clustering of Applications with Noise (DBSCAN) automatically scans the dataset for groupings. Furthermore, unlike K-Means, it is non-linear which means it could identify groupings of different sizes and complex shapes.
As we moved further into the course, we progressed to more interesting and useful algorithms, notably, decision trees. Decision Trees can be used for both regression and classification problems. It works by learning key rules in the data and using them to predict an outcome. Decision Trees are made up of branches. In each branch, the output depends on one of the features in the data. The output of that branch is then fed to the next layer of branches, and so on until it reaches an output state.
Finally, towards the end of the course, we started an introduction to deep learning and neural networks. So far, all the algorithms we had been studying in the course were considered in the broad category of machine learning. Deep Learning is a subclass of machine learning based on artificial neural networks. We went through the basics of 3 neural networks before the course came to a wrap. Feed Forward Neural Networks, the simplest type of neural network which works with any numerical data that does not follow a sequential pattern. Convolutional Neural Networks (CNNs), which work on images and other multidimensional data, and finally Recurrent Neural Networks (RNNs), which can process sequential data like sound waves data and other features that change over time.
Course Project – Malaria Detection using Deep Learning with TensorFlow and Keras
As part of the course, each student had to come up with a culminating project that applied learnings from the classes. My project was on “Malaria Detection using Deep Learning with TensorFlow and Keras”. It compared the use of 3 different machine learning algorithms to detect the signs of malaria in human blood film samples. In the end, I managed to train a Convolutional Neural Network (CNN) to detect malaria with an accuracy of nearly 96%. In the last class of this course, I also gave a presentation about my project to the entire class and fielded questions at the end of my presentation. It was an amazing experience to deliver a presentation about my project in a university classroom. I was already looking forward to the next course!
Project 1: Malaria Detection using Deep Learning with TensorFlow and Keras
Now that I had a solid grounding in machine learning and was able to apply it to health projects, I proceeded to the second course of the artificial intelligence certificate program: SCS 3546 Deep Learning. This course would go into the theory and practice of modern neural networks and hyperparameter tuning. It was being taught by Sina Jamshidi, a senior data scientist and machine learning expert with over 10 years of experience leading AI projects in telecommunication companies such as TELUS and Bell. The structure of the class was similar to that of the first course- half theory and half practice. This time, we would be intensively using the TensorFlow library. TensorFlow is a deep learning library by Google that simplifies the creation and training of neural networks in Python.
In the first class of this course, we dived right into the ‘perceptron’, the building block of neural networks. To solidify our practical learning, we started running short demo notebooks and going through the usage of TensorFlow as well as Keras, another deep learning library that runs with TensorFlow.
In the subsequent classes, we gained an in-depth understanding of the layers in a Convolutional Neural Network (CNN) and learned about the recent state-of-the-art CNNs such as AlexNet and ResNet and why they performed so well. Best of all, we were even able to visualize the features and heatmaps being picked up by CNN when it looked at an image and interprets it. This was especially interesting since, in the past, neural networks had often been regarded as a “black box” that is unexplainable. But this module opened our eyes to the similarities between our understanding of an image versus how a CNN analyzes an image. For example, just like humans, one of the first features a CNN picks up when looking at a picture of a cat is the edges of the animal and its eyes.
During the course, we learned about advanced types of Recurrent Neural Networks (RNNs) like Long-Short Term Memory cells (LSTMs). Unlike the classic RNN cells, LSTMs have feedback connections within the neural network, which enable it to process entire sequences at once instead of one value at a time. This means it gets a better understanding of which parts of the sequence are more important than others. Another interesting thing we learned was bi-directional RNNs. Unlike normal RNNs which only read a sequence in one direction, bi-directional RNNs analyze a sequence in both directions. This means at any point in a sequence, it understands its relation to information before it, and after it. This is very useful in solving problems, for example, in which a model must predict the missing word in a sentence. To get the context of the sentence and find the most appropriate missing word it will have to analyze the words before the missing word, as well as the words after it.
This module matched well with the next part of the course on Natural Language Processing (NLP). This is where we were taught about tackling the ambiguity and complexities in analyzing the human language logically using deep learning models. Unlike applying machine learning models with the imagery data, it is not as simple as plugging the raw data into the model and training it. For one thing, a corpus linking each word to a token, or a number must be established. Then there are the added complexities of synonyms, punctuation, contractions (a shortened version of the spoken and written forms of a word), words that have double meanings, and so on. We learned how to preprocess the text data to work around these issues and successfully train an accurate NLP algorithm over a period of a few classes.
We then moved on to another useful neural network- the autoencoder. Autoencoders learn to efficiently encode unlabeled data into a smaller latent space and decode it with minimal loss of important data. Autoencoders have numerous applications from anomaly detection to dimensionality reduction. This is also one of the primary algorithms I ended up using in my term project later in this course.
The last topic we touched upon in this course was Generative Adversarial Neural Networks (GANs). GANs are machine learning algorithms that can generate new synthetic images that look like images it has been trained on. A GAN is made up of 2 neural networks- the Generator and the Discriminator. The Generator trains on the database of images provided and tries to create similar images. The Discriminator trains itself to discriminate between real images and images created by the Generator. A GAN trains in a loop: the Generator generates fake images to fool the Discriminator, which in turn tries to recognize those fake images and provide feedback to the Generator to help it improve and create more realistic images. We explored different variations of GANs like Deep Convolutional GANs. Even more, interestingly we learned about Info GAN- a type of GAN that can not only generate fake images but also generate them with specific features. For example, if it was trained on a label database of human faces, it can learn to generate human faces with features like mustaches, beards, different skin tones, and so on. To wrap up the module, we went through a few other generated machine learning algorithms like Pixel RNNs and Fully Visible Belief Nets.
Deep Learning Project –Face Classification using Autoencoders and Support Vector Machine
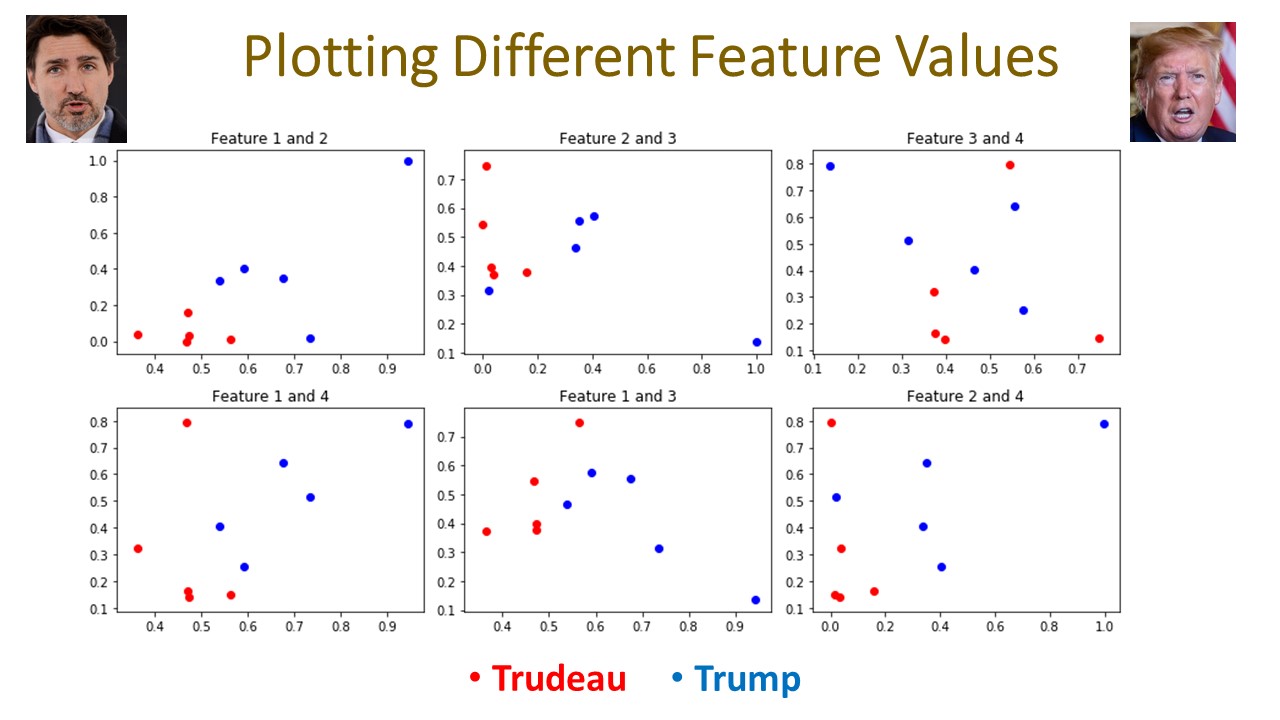
For this course term, my project was a bit more complex as I was now more experienced having successfully completed and presented my first project. I had learned a lot about facial recognition and many state-of-the-art models that could accurately identify human faces. But these models are trained on hundreds of thousands of images to work that accurately. I wanted to create an algorithm to identify different people with only a handful of images. I ended up merging an autoencoder model with a support vector machine but was successfully able to create an algorithm that could differentiate between the faces of Canadian prime minister Justin Trudeau and the former American president Donald Trump after seeing only a few images of each.
Project 2: Face Classification (Trump and Trudeau) using Autoencoder and Support Vector Machine
Finally, in May 2020 I started the last of the 3 courses in the artificial intelligence certificate program: SCS 3547 – Reinforcement Learning. This three-month-long course was very different from the previous two that focused on supervised deep learning algorithms and required labeled examples to train on. Reinforcement learning is different from supervised learning. Here the training of machine learning agents happens through trials and errors. This includes agents that can learn to play games and agents that must use inference and probabilistic reasoning to make decisions in new environments. Because of the COVID-19 pandemic, I took this course online. Fortunately, the teacher, Larry Simon, an entrepreneur, and angel investor specializing in data analytics and machine learning made sure that the transition to online learning was seamless and we were able to benefit from the same theoretical and practical experience that was offered in in-person classes.
As this was a new and complex topic, the first couple of classes were more theoretical and focused on allowing us to grasp the concept of reinforcement learning agents properly. We learned the many steps in an intelligent agent, from receiving sensory inputs from the environment it is in, to trying to optimize a certain encouragement score or an indicator of how well it is performing in an environment. One of the most interesting concepts I took from these lessons was the importance of curiosity. In an environment, a model might find an optimal way to maximize its score. But it is very possible there is another method that could potentially allow it to perform exponentially better. That is why, even when the performance score is high, an intelligent agent must leave some room for exploration of new methods that could allow it to perform even better.
During this course, we started on our first Reinforcement Learning algorithm: the Monte-Carlo Tree Search. This simplistic method uses random sampling to play a game or explore an environment several times with no intelligence. It then adjusts itself so that the moves that led to more favorable outcomes are given a higher weightage. It repeats this process several times until it can develop a method of winning or achieving a high score every time. The disadvantage of this method is that it is very time-consuming, especially in games with a much larger realm of possibilities like Chess or AlphaGo.
We then continued into more complex and efficient methods like Mini-Max. the Mini-Max algorithm works by working backward from the end of the game. At each step, it assumes the opponent is making an optimal move, or in other words, minimizing the algorithm’s performance score. Based on that assumption, it makes a move that attempts to counter the opponent’s move and maximize its own score. While more efficient than the Monte-Carlo search, it is still time-consuming for more complex games.
Through the course, one of the hardest things we had to do was create the virtual environment that our reinforcement learning agent would work in. While the agent’s job is the learn to maximize its feedback score, it is the virtual environment that must execute the move selected by the agent and calculate the feedback score, as well as determine when the agent has won or lost. Some of the game environments we explored were Hexapawn, a simple game like tic tac toe, as well as AlphaGo, a popular testing ground for reinforcement learning agents.
In the last half of the course, we got to the most interesting method- deep reinforcement learning. While all the previous reinforcement learning algorithms relied on probabilistic mathematics and human-made methods, deep reinforcement learning learns through a deep neural network. Either the neural network is trained in one go, or it learns as it goes.
One of the deep reinforcement learning algorithms we learned was Dyna-Q. It starts by taking a random move in an environment and receiving the feedback score. It then adds the move it made and its corresponding feedback score to its database and trains itself. For every subsequent move, it repeats this process and continuously re-trains itself to become better at maximizing the feedback score. Another algorithm we worked upon was Policy Networks. A policy network does not directly predict the move an agent should take, but rather trains itself over time to compute a table with a direct optimal move for every possible situation. Unfortunately, similar to some of the more classic reinforcement learning algorithms, it does not work well for environments that have a lot of possibilities.
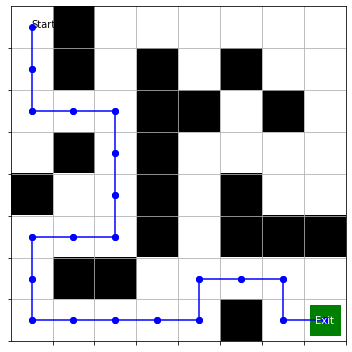
Reinforcement Learning Project – Labyrinth Solving with Reinforcement Learning
Project 3: Labyrinth Solving with Reinforcement Learning
For my term project this time, I created a deep reinforcement learning algorithm that could find its way out of a labyrinth. The Agent should be able to drop into any state in the maze, and close to optimally find the exit. To calculate the Q-Values, it would have to explore the maze environment several times and learn the optimal direction to take depending on which state it is on. It would have to find the correlation between the (X, Y) coordinates and the correct direction to go.
This was the most complex term project so far for me, as reinforcement learning was a completely new topic to me. It took me a lot of time to complete this project as I had to codify and visualize the entire maze myself. This included the classes for placing the obstacles, calculating the possible moves, and displaying the path the agent was taking. It was definitely the most fun and challenging project and I enjoyed every aspect of it.
I am glad I made the move to enroll myself in these courses even though I was in Grade 7. The atmosphere was very welcoming, and the community was friendly Everyone was there to learn and apply their learning to projects of their choice. This created an environment conducive to learning for the love of a subject. The instructors of all the courses were very dedicated and driven. They encouraged asking questions and often a group of students would gather around the instructors at the end of class to learn more or to ask more detailed questions. We got regular feedback on our projects, and everyone was encouraged to make presentations about their projects. I enjoyed every aspect of the project from pedagogy to how the course was delivered and support is given at every instance. I hope to take up new courses offered by the University on machine learning in the future too.
Once I completed all the three required courses, assignments, and projects for the Artificial Intelligence certification at the University of Toronto School of Continuous Studies, I awaited the results. I scored an aggregate of 90% for the course and was satisfied with my progress and learning. I was happy to have completed the course requirements by the time I completed Middle School. Unfortunately, because of the COVID-19 pandemic and closure of the university, the University of Toronto Certificate on Artificial Intelligence arrived a year later. It was worth the wait as my learning never stopped even after completion of the courses.
I continue to apply learnings from these courses to the ongoing and new projects I undertake as I believe that the best way to learn is to keep doing challenging projects, document them, and then teach others.
Notably, while taking the second course (SCS 3546 – Deep Learning), I applied my learnings about the use of the Keras Functional API in my project on “Using Machine Learning to Remove Noise from Stellar Spots in Exoplanetary Data from Space Telescopes”. My project used a hybrid machine learning algorithm made up of an LSTM Recurrent Neural Network and a Feed-Forward Neural Network to remove noise from stellar spots in simulated exoplanetary light curve data from the Atmospheric Remote-sensing Infrared Exoplanet Large-survey. This project ended up winning a Gold Medal at the INSPO North America Science Fair 2020. My report from this project was also published in the Canadian Science Fair Journal (Volume 3, Issue 5, 2021): https://csfjournal.com/volume-3-issue-5/2021/2/21/using-machine-learning-to-remove-noise-from-stellar-spots-in-exoplanetary-data-from-space-telescopes
2025 Third Grand Award, International Science and Engineering Fair, USA. 2023 Second Prize Winner – European Union Contest for Young Scientists (EUCYS). Best of the Fair Award, Gold Medal, Top of the Category, Youth Can Innovate, and Excellence in Astronomy Awards at Canada Wide Science Fair 2023 and 2022. RISE 100 Global Winner, Silver Medal, International Science and Engineering Fair 2022, Gold Medal, Canada Wide Science Fair 2021, NASA SpaceApps Global 2020, Gold Medalist – IRIC North American Science Fair 2020, BMT Global Home STEM Challenge 2020. Micro:bit Challenge North America Runners Up 2020. NASA SpaceApps Toronto 2019, 2018, 2017, 2014. Imagining the Skies Award 2019. Jesse Ketchum Astronomy Award 2018. Hon. Mention at 2019 NASA Planetary Defense Conference. Emerald Code Grand Prize 2018. Canadian Space Apps 2017.