The Space Science in Context 2020 is a virtual conference bringing space and science and technology studies (STS) scholars together for an interactive event. It was held on 14 May 2020.
 The conference had three sessions–Decolonizing Space; Computing, Technology and Space; and Space for Society and brought together 12 speakers and 30 poster presenters at different times in a video-chat hybrid format.
The conference had three sessions–Decolonizing Space; Computing, Technology and Space; and Space for Society and brought together 12 speakers and 30 poster presenters at different times in a video-chat hybrid format.
Artash Nath presented his poster “Will Machine Learning Algorithms Take their Bias to Space?” at the conference.
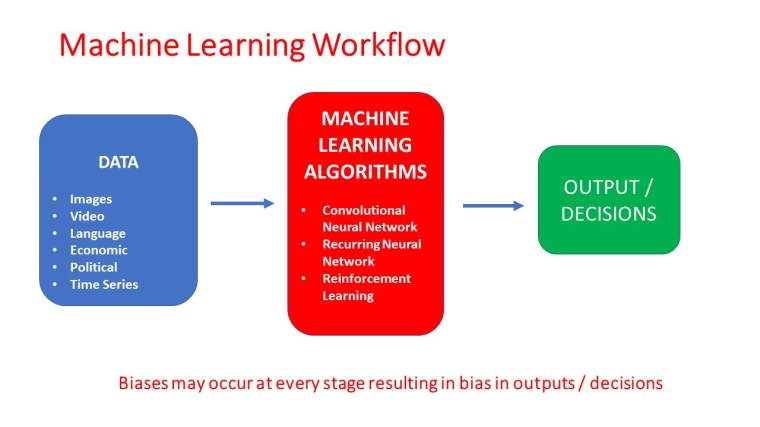
Machine Learning algorithms are data intensive. They need lots of data to learn before they can perform tasks without human intervention. Earth-based machine learning models, be it autonomous cars, facial detection, or emotions assessment algorithms have biases based on age, gender, citizenship, and race.

The bias in machine learning may occur because of:
1. Choice of training data that serves as input to the machine learning models
2. Biases in labeling or interpretation of the data
3. Biases in the design of machine learning algorithms
4. Biases in supervision or reinforcement of results produced

As more countries accelerate their space exploration programs to bring more humans to the lower earth orbit, back to the Moon, to Mars and beyond, we are seeing a rise in the use of machine learning in space-based applications.
Artificial intelligent robots (CIMON and Kirobo) have already made trips to the International Space Station. Over time, we will see more rovers, spacecraft operations, scientific experiments, and astronaut health and safety systems embedding artificial intelligence and turn autonomous.

With the rise in machine learning applications in the space sector including in robot autonomy and human space exploration will these earth-based biases persist in space? If so, how to reduce bias in the machine learning applications?
How to Reduce Biases?
A way out to reduce biases in machine learning would be to move away from algorithms that rely on huge datasets for training quickly and in one-shot. Instead, the focus could be on training machines slowly and in immersive environments that are multicultural and are free from biases. Ethics, rule of law and human rights should be embedded in every data and information transmitted to the machines.

Greater use of logic and probability should be encouraged in training machines to reduce reliance on large datasets.
The machines should be trained to ask questions when the training set or input information does not match the embedded ethics and human rights code.
Lastly, we should be progressive. We need to train machines based on the world we would like to see: fair, just, and providing equal opportunities to all, instead of the world we currently live in.

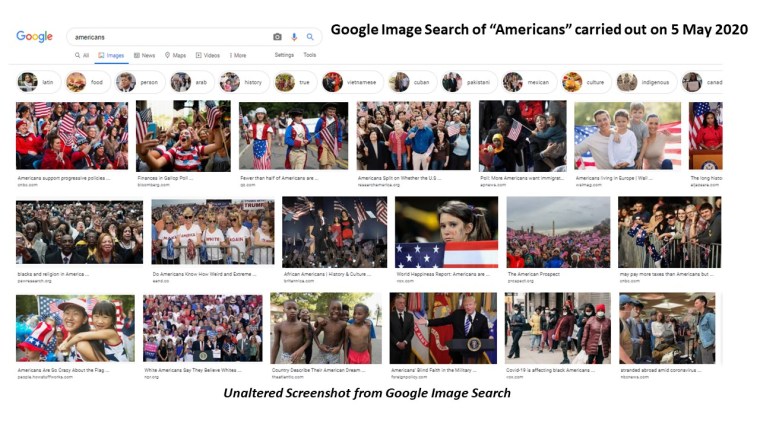
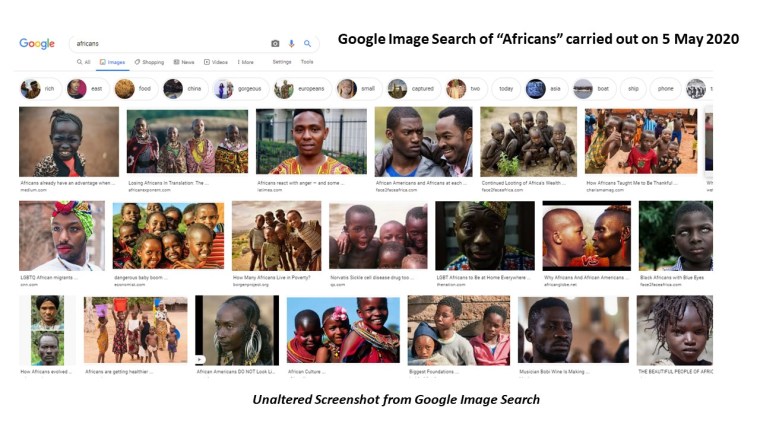


The conference was organized by Eleanor Armstrong and Divya M. Persaud from the University College of London. They made inclusiveness and accessibility a part of the conference. All invited speakers’ videos were closed-captioning accompanied by a full transcript. Poster speakers were required to have screen-reader friendly posters that included full image descriptions.




















































































































































































































































































