Artash Nath, Grade 8 Student. Brainhack is a conference related to neuroscience that happens globally. The objective of Brainhack is to advance brain science research. And it does so by […]
Artash Nath, Grade 8 Student.
Brainhack is a conference related to neuroscience that happens globally. The objective of Brainhack is to advance brain science research. And it does so by bringing together neuroscience research, data science, and increasingly machine learning communities. For the last few years, global Brainhack events have brought together these communities in open collaboration while regional Brainhack events keep the momentum going throughout the year.
Artash at BrainHack Toronto at the Krembil Centre for Neuroinformatics for Python Workshop on Neuroimaging
Progress accelerates in a collaborative and interdisciplinary environment. And this is the intention behind BrainHack Toronto. BrainHack Toronto is happening at the Krembil Centre for Neuroinformatics in Toronto from Nov 13 – 15, 2019. The theme of Brainhack Toronto this year is “Individuality in the Age of Big NeuroData.” It is an effort to advocate for the exploration and development of tools related to inter- and intra-individual variability across multiple scales (gender, sex, diagnosis, etc…).
The three-day event is a mix of Python Neuroimaging Workshop, Panel Discussions (on Science and Industry), Guided Projects to get participants up to speed with collaborative programming within neuroscience, and a Neuro-Hackathon! The format of the event is designed to ensure that participants with different knowledge levels on neuroscience can appreciate developments in the neuroscience informatics and imaging, datasets available, challenges faced, and ongoing approaches to solving them.
BrainHack Toronto 2019 Sponsors
Day 1
Over 50 participants turned up on Day 1 of the event. It was an interesting mix of neuroscience experts, data experts, tech experts and simply enthusiasts on this subject.
I have been working on neural networks and machine learning for over a year and on Python programming for the last two years. I registered myself for this event so as to learn more about neuroscience, big data available in this sector, and some of the most pressing data-related challenges in neuroscience. So far I have worked with big data on space and astronomy projects. I wanted to see what are the similarities and difference in data challenges faced by these two distinct communities, and what learnings I can apply from the space sector to the neuroscience sector, and vice versa when it came to big data!
BrainHack Toronto Workshop in progress: it was a full house
Session 1: BrainHack Intro to BIDS and MRI Workshop
The event was kick-started by Dr. Erin Dickie, the Chair of BrainHack Toronto and Project Scientist at Kimel Family Translational Imaging-Genetics Laboratory (TIGRLAB). A big thanks to Erin and her team for organizing this awesome, inclusive and friendly event.
Erin focused on the issue of data organization standards in neuroimaging. At present neuroimaging experiments generate data that are arranged in different ways and are not compatible with each other. This means data cannot be fully analyzed and a lot of research time gets used in rearranging data to make them compatible and comparable. Thus the need for data standards that are intuitive, easy to understand and deploy.
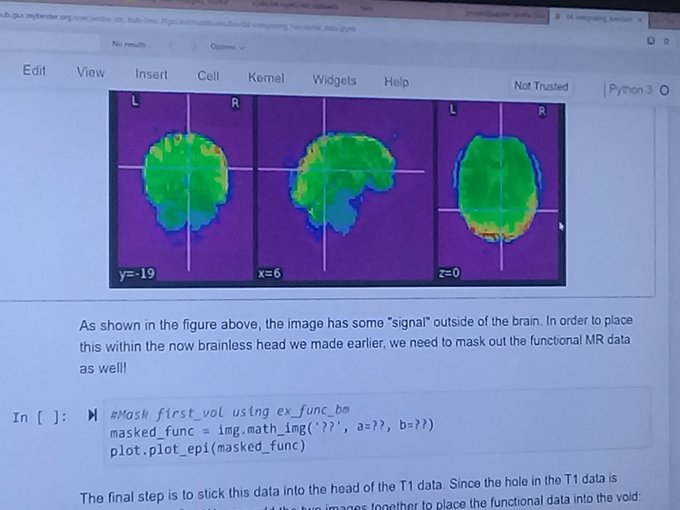
Learning about Image Manipulation Functions in Python (creating brainless heads and more)
One such standard is the Brain Imaging Data Structure (BIDS). BIDS is based on a formalized file/folder structure for neuroimaging and behavioral data. It was inspired by the format of the OpenfMRI repository (now known as OpenNeuro.org). It formalizes the use of common practices such as encoding the purpose of a file in its filename and using widely recognized file formats such as NIfTI, JavaScript Object Notation [JSON], and Tab Separated Value [TSV] text files.
I learned a lot and ended up appreciating, even more, the frustrations of having data but not in the format where it could be analyzed. While magnetic resonance imaging (MRI) techniques are routinely used as non-invasive procedures to obtain data of the brain, there is no widely adopted technique for organizing and describing the data collected through this procedure. I could draw parallels from my own machine learning projects where the bulk of my time gets used in data preparation and resolving the incompatibility between different data sources.
The workshop sessions were now taken over by Jerry Jeyachandra and Michael Joseph. Jerry and Michael work as Research Analyst at the Kimel Family Translational Imaging-Genetics Laboratory (TIGRLAB). They both had extensive experience on computational pipelines, image processing and software control related to MRI.
As with all subjects, one of the first things to learn is abbreviations. fMRI stands for Functional Magnetic Resonance Imaging or functional MRI (fMRI). And it is not difficult to understand what is it does. It is based on the simple principle that when an area of the brain is in use, then the blood flow to that region increases. Thus there is a link between neuron activation in the brain and the blood flow in the brain. fMRI measures brain activity by detecting changes in the blood flow.
The workshop brought together an amazing community: neuroscientists, data and tech community. It led to many conversations to seek more knowledge.
So how is it different from MRI? The MRI generates 3D scans of the brain. They are like static 3D images. fMRI adds a time dimension to these images as it is detecting changes in the blood flow. This results in the creation of activation maps that show which parts of the brain are activated at what time.
The workshop introduced us to Neuroimaging Informatics Technology Initiative or NIfTI files. NIfTI is one of the most ubiquitous file formats for storing neuroimaging data. We learned how to pre-process fMRI data, how to open NIfTI files into Python, and how the data is stored in these files. These are essential steps before we can carry out any analysis of data or manipulation of images.
The workshop used a subset of a publicly available dataset, ds000030, from openneuro.org Interestingly, this dataset and others hosted on OpenNeuro are structured according to the BIDS format making it easier to work on them.
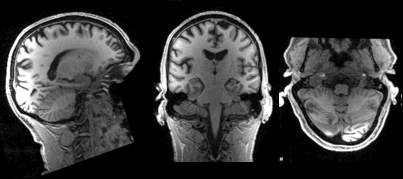
An MRI Scan from the Open Database
The workshop touched upon several functions we could use to manipulate MRI images such as creating a brainless head and headless brain, identify different parts of the brain, looking at MRI images from different points of view, and slicing the brain along different axes. We learned about how to apply these functions to multiple brain images instead of only one.
Diffusion Magnetic Resonance Imaging (DMRI) is one of the techniques to explore neurological diseases. Here the diffusion of water molecules in tissues is used to generate contrast in MR images. This part of the workshop was a continuation of the Python workshop on fMRI images.
Learning about Voxels or volume pixels (the smallest distinguishable 3D unit of the brain) and analyzing them was my favorite part.
Again, we learned how manipulation can be done on DMRI images. It used the same libraries as was the case with fMRI analysis. We learned about querying the data, dimension reductions, taking 2D images out of 3D scans, understanding the signal intensity of the voxel at coordinates. Voxels or volume pixels were my favorite part. Voxels are the smallest distinguishable box-shaped part of a three-dimensional image that is generated in an MRI scan. We learned about flipping color scales so that black portions appear white and vice versa.
The great thing about the workshop was that it was carried out using a Jupyter notebook. This meant it was easier to follow and lots of exercises were embedded in the workshop for participants to try and become familiar with.
In a matter of a few hours, I was able to go from knowing very little about MRI images, open databases and file standards to be able to open and work on those files in Python and manipulate the images for analysis. I can now build up my knowledge on these images on my own by following the resources suggested and trying out all the exercises in the Jupyter notebook for this workshop.
Session 4: Project Pitches
The end of the workshops marked the start of the Project Pitch Pizza Party! We bonded over pizza and learned a lot more about each other. We even had a session where each of us spoke a little bit about ourselves, our work and what brought us to the Brain Hack. Kudos to the organizer to have brought together such an inspiring and knowledgeable group together. I learned a lot by listening to and speaking with other participants.
Guided Projects and Project Pitches in progress for the NeuroHackathon
There were some interesting project pitches and project ideas to lay the framework for the next two days of the hackathon. Pitches ranged from improving software that could label cells on its own to my favorite one: mapping the mouse brain to the human brain. For instance, if treatment in a mouse causes brain region A to change in structure, can we predict which regions in the human brain will show a similar change, if at all? The discussions on eigenvectors for mapping coordinate in one species to (potentially multiple) coordinates in the other species, reminded me of some of the techniques I used in creating simple to more complex machine learning models and various activation functions.
Project pitches ranged from software that could label cell on its own (by Nick Wang in the picture) to mapping mouse brain to the human brain
Some of the ideas that came into my mind were while we can apply machine learning to solve some neuroscience data challenges can we actually learn more about our brain by taking lessons from artificial intelligence. I hope to learn more, build and discuss newer ideas over the course of the hackathon.
2025 Third Grand Award, International Science and Engineering Fair, USA. 2023 Second Prize Winner – European Union Contest for Young Scientists (EUCYS). Best of the Fair Award, Gold Medal, Top of the Category, Youth Can Innovate, and Excellence in Astronomy Awards at Canada Wide Science Fair 2023 and 2022. RISE 100 Global Winner, Silver Medal, International Science and Engineering Fair 2022, Gold Medal, Canada Wide Science Fair 2021, NASA SpaceApps Global 2020, Gold Medalist – IRIC North American Science Fair 2020, BMT Global Home STEM Challenge 2020. Micro:bit Challenge North America Runners Up 2020. NASA SpaceApps Toronto 2019, 2018, 2017, 2014. Imagining the Skies Award 2019. Jesse Ketchum Astronomy Award 2018. Hon. Mention at 2019 NASA Planetary Defense Conference. Emerald Code Grand Prize 2018. Canadian Space Apps 2017.


 Brainhack
Brainhack